設定のかえかた
「ひらがなIMEの設定」ウィンドウ
「ひらがなIME」の設定は、「ひらがなIMEの設定」ウィンドウでおこないます。トップバーのキーボード メニューから[設定]をえらぶと、「ひらがなIMEの設定」ウィンドウがひらきます。
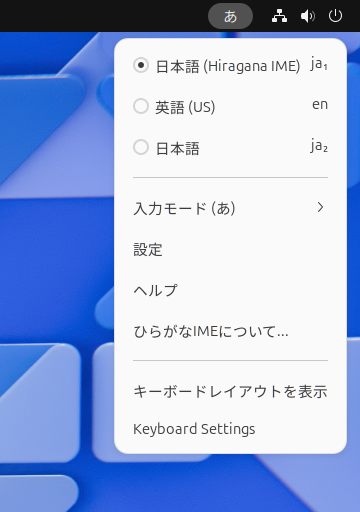
「ひらがなIMEの設定」ウィンドウには、つぎの3つのタブがあります。
| 説明 | |
|---|---|
| キーボード | ローマ字入力とかな入力のきりかえをおこないます。 |
| 辞書 | 使用する漢字辞書をえらびます。 |
| オプション | 追加の設定をします。 |
設定した内容は、[OK]ボタンか[適用]ボタンをおせば「ひらがなIME」にすぐ反映されます。
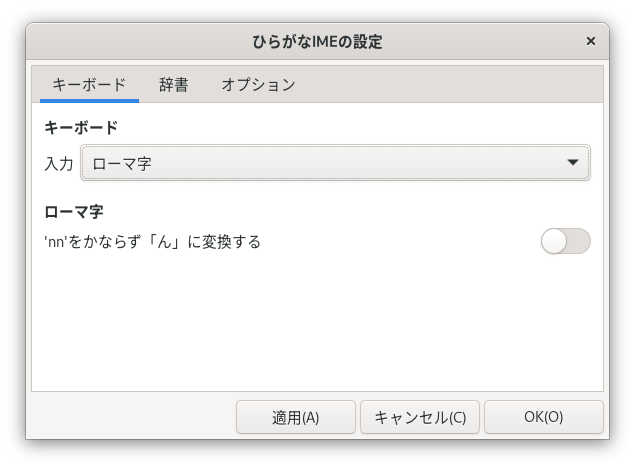
キーボード タブ
キーボード タブでは、日本語の入力方法を設定します。
キーボードの打ちかたを「入力方法」ドロップダウンリストからえらびます。つぎの3種類からえらべます。
| 入力方法 | 説明 |
|---|---|
| ローマ字 | ローマ字で入力します。 |
| かな (JIS配列) | JISかな配列をつかって入力します。 |
| ニュースティックニーかな配列をつかって入力します。 |
日本語の文章をキーボードで入力するときは、かな入力とローマ字入力がよくつかわれています。ローマ字入力は小学校3年生から学校でおそわります。かな入力であれば、ローマ字がわからなくても、つかうことができます。
'nn'をかならず「ん」に変換する
「ん」をいつも「nn」で入力したいときは、『'nn'をかならず「ん」に変換する』をオンにします。
| オプション | 入力 | 出力 |
|---|---|---|
| オン | konnnitiha | こんにちは |
| オフ | konnitiha | こんにちは |
注意: ふるいワープロでは、「nn」と入力すると「ん」になる便法がつかわれてきました。これは、ローマ字のつづりかたとしては、ただしくありません。これをさだめたJIS規格X4063は2010年に廃止されています。
辞書タブ
辞書タブでは、漢字変換につかう辞書を設定します。
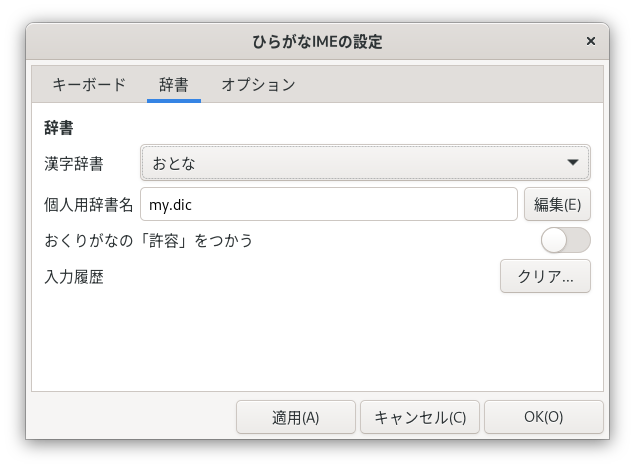
漢字辞書
使用する漢字辞書は、[漢字辞書]ドロップダウンリストをひらいてえらびます。「ひらがなIME」は、おとな用の漢字辞書のほかに、小中高生用の辞書を用意しています。学年別の漢字辞書の詳細については「ひらがなIMEの辞書」で説明しています。
個人用辞書名
個人用の辞書に登録しておけば、標準の漢字辞書にない単語も変換できるようになります。個人用辞書は、複数のファイルをつかいわけることができます。[個人用辞書名]テキストボックスには、利用したい個人用辞書のファイル名を指定します。はじめは my.dic というなまえになっています。個人用の辞書ファイルは、ディレクトリ ~/.local/share/ibus-hiragana/ のなかに保存されています。
個人用辞書ファイルは、[編集]ボタンをおすと編集できます。ファイルのかきかたについては、「辞書ファイルのかきかた」で説明しています。
おくりがなの「許容」をつかう
スイッチをオンにすると、『送り仮名の付け方』で許容されているおくりがなをつかえるようになります。オフにしているばあいや、おとな用以外の辞書をつかっているときは、学校でならう本則だけをつかいます。
例) おくりがなの「許容」をつかうと、下の表にしめしたような変換ができます。
| 本則 | 許容 |
|---|---|
| お変換とす → 落とす | おと変換す → 落す |
| おこな変換って → 行って | おこ変換なって → 行なって |
| とど変換けで変換 → 届け出 | とどけで変換 → 届出 |
「行って」と「行って」は本則のままではふりがながないと区別ができません。ぎゃくに、漢字をよくしっているひとが「落す」をよみあやまることはありません。和語(ほんらいの日本語)に漢字をあててかくのは、なかなかむずかしいことです。この手びきでは、和語はなるべくひらがなでかくようにしています。
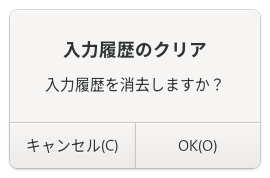
入力履歴
変換候補ウィンドウでは、よくつかう同音異義語やよみを短縮したことばが一覧のはじめのほうにきます。これを初期状態にもどしたいときは、[クリア...]をクリックします。そして、つぎのメッセージボックスが表示されたら、[OK]ボタンをおします。
オプション タブ
オプション タブでは、入力を補助する機能の設定ができます。
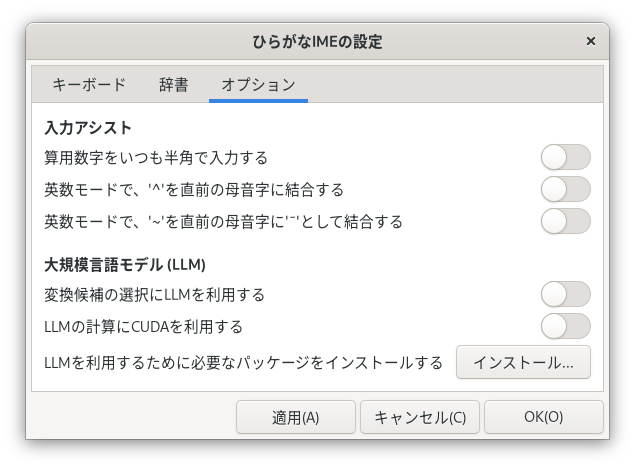
算用数字をいつも半角で入力する
オンにすると、かな入力モードでも算用数字を半角で入力します。
| 設定 | 例 |
|---|---|
| オフ | 12、345。678 |
| オン | 12,345.678 |
英数モードで、'^'を直前の母音字に結合する
日本語を訓令式ローマ字でかきあらわすときは、このスイッチをオンにすると便利です。
英数モードで^を入力したときに、直前の文字が母音字であれば、母音にサーカムフレックスをつけます。
- 例: a^ → â
直前の文字がサーカムフレックスつきの母音字のときに、^を入力すると、直前の文字を母音字と単独のサーカムフレックスにわけます。
- 例: â^ → a^
英数モードで、'~'を直前の母音字に'¯'として結合する
日本語をヘボン式ローマ字でかきあらわすときは、このスイッチをオンにすると便利です。
英数モードで~を入力したときに、直前の文字が母音字であれば、母音にマクロンをつけます。
- 例: a~ → ā
直前の文字がマクロンつきの母音字のときに、~を入力すると、直前の文字を母音字と単独のチルダ(~)にわけます。
- 例: ā~ → a~
変換候補の選択にLLMを利用する
オンにすると、文脈にあった変換候補があらかじめ選択されるようになります。たとえば、「かいとう」を漢字に変換するときは、文脈に応じてつぎのように選択されている候補がかわります。
- アンケートにかいとう変換 → アンケートに回答
- 問題のかいとう変換 → 問題の解答
LLMの計算にCUDAを利用する
オンにすると、LLMをつかった変換候補の出現確率の計算にCUDAを利用します。PCにNVIDIA社のGPUが搭載されていれば、変換キーをおしてから候補がでてくるまでの時間を短縮できます。
注意: CUDAを利用するには、NVIDIAのドライバーがインストールされている必要があります。最近では、UbuntuやFedoraの公式リポジトリから、必要なドライバーが提供されるようになってきています。問題なくインストールできていれば、ひらがなIMEの「情報ダイアログボックス」に使用しているGPUのモデル名が表示されます。
LLMを利用するために必要なパッケージをインストールする
[インストール...]をおすと、LLMをつかうために必要なパッケージをインストールできます。くわしくは「大規模言語モデルのインストール」をみてください。